-
[3]GAN-Generative Adversarial Nets논문 공부 2022. 4. 11. 14:06
GAN
GAN은 Generative Adversarial Nets의 준말로써 생성적 적대 네트워크 입니다.
GAN은 기존의 CNN과 달리 두개의 모델을 학습시키며 각 모델은 Generator와 Discriminator로 나누어져있습니다.
우선 Generator는 랜덤으로 생성한 noise를 input으로 하여 Real data와 유사한 이미지를 생성하도록 학습하며,
Discriminator는 Real data와 Generator가 생성한 데이터중 랜덤데이터를 Input으로 받아 Real data인지 Generated data 인지를 판별하도록 학습합니다.

상단이 GAN이 학습을 진행하는 프로세스입니다. 해당 프로세스에서 초반의 Generator는 Real data를 모방하는 품질이 좋지 않을테니 Discriminator가 쉽게 판별할 수 있으며, 이를 통해서 Generator가 Real data를 모방하는 품질을 더 정교하게 만듭니다.
해당 작업을 반복했을때 결국 Generator가 Real data와 완벽히 같은 데이터를 생성해내게 되고, Discriminator는 True, False 두가지 선택지에서 반반의 확률로 맞추게 되는 상황이 나타납니다.
이 상황이 GAN이 최종 목표로 하는 학습단계이며, 이를 위해서는 sampling이 필요합니다.
sampling이란 Generator가 Real data를 모방하기위해서 Real data의 분포가 어떤지 추론해보는것입니다.

Pdata(x) = real data의 분포, PG(x) = Generator output의 분포 Pdata(x) 와 PG(x)를 비교해 보았을때 전체적인 형태는 비슷하지만 아직은 차이가 있는것을 볼 수 있습니다. 이런 상황에서 최대한 비슷한 분포를 만들도록 훈련을 반복하는것이 sampling입니다.

검은 점선 = real data의 분포, 초록 실선 = generator output의 분포, 파란 점선 = Discriminator의 분포 그렇게 훈련을 반복하다보면 (a) -> (b) -> (c) -> (d) 의 변화를 보이며, 이는 최종적으로 (d)의 모습처럼 Real data와 Generator output의 분포가 같아지는 상황이 됩니다. 이 상황에서 파란 점선은 일정한 0.5의 수치를 가지며 이는 True, False 두가지 50% 확률로 판별해내는 최종 학습상황을 이야기합니다.
이렇게 최종 학습상황을 만들기 위해서는 Loss를 최적화 시켜야 합니다.
GAN Loss

상단의 수식이 GAN에서 사용하는 Loss function 입니다.
이중에 A부분은 Generator의 Loss, B부분은 Discriminator의 Loss입니다.
수식을 해석해보자면,
A : Real data값을 Discriminator에 넣어서 log취한값의 기댓값
B : Generator에서 생성된 output을 Discriminator에 넣은값을 1에서 빼서 log취한값의 기댓값으로 해석됩니다.
즉, 실제 데이터를 Discriminator가 진짜라고 판별 할 확률 + (1 - Generator가 만든 가짜데이터를 Discriminator가 진짜라고 판별 할 확률)
-> 실제 데이터를 Discriminator가 진짜라고 판별 할 확률 + Generator가 만든 가짜데이터를 Discriminator가 가짜라고 판별 할 확률
=> Discriminator가 실질적으로 모든 데이터가 어떤 데이터인지 맞출 확률이 됩니다.
그렇기 때문에 Generator는 해당 Loss function을 최소화해야하고, Discriminator는 Loss function을 최대화 해야합니다.
하지만 논문에서 설명하기를 log(1-D(G(z)))를 최소화해서 Generator를 학습하는 것 보다, log(D(G(z)))를 최대가 되도록 학습하는것이 더 좋다고 설명하고 있습니다.
그 이유는 학습 초기에 Generator의 성능이 떨어지기 때문에 log(1-D(G(z)))의 값이 log(0.00000.....01)이 되므로 -무한대에 가까운 수가 되므로 학습이 제대로 되지 않기 때문입니다.
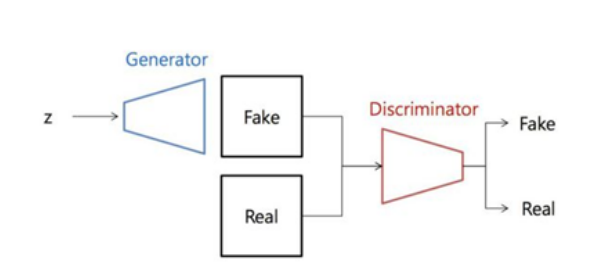
상단의 이미지처럼 Generator는 z(랜덤 생성된 노이즈)를 Input으로 받으며 Fake 이미지를 생성합니다.
그후 생성한 Fake 이미지와 Real 이미지를 Input으로 하여 Discriminator는 sigmoid 함수를 activation으로 Fake Real을 판별합니다.
Experiments
Dataset : MNIST, TFD(Tronto Face Database), CIFAR-10
Activation Function : G -> ReLU, sigmoid , D -> maxout
학습 후 생성 된 Generator의 이미지들은 아래와 같습니다.

해당 논문은 이러한 샘플들이 기존의 방법들에 의해 생성된 샘플들보다 좋다고 주장하지는 않지만, 이러한 샘플들이 적어도 기존의 생성 모델과 비교할만 하고 adversarial 프레임워크의 잠재력을 강조한다고 믿는다.
'논문 공부' 카테고리의 다른 글