-
[2]Rethinking the Inception Architecture for Computer Vision (Inception-v2~3) - 2016논문 공부 2022. 3. 15. 13:09
Rethinking the Inception Architecture for Computer Vision은 Inception의 새로운 버전 v2, v3를 서술하고 있습니다.
일반적인 상황에서 Inception v1은 좋은 결과를 얻었지만 구조의 복잡성으로 인해 개선하기가 어려웠습니다.
그래서 Inception v1을 최적화 하기 위한 모델 최적화 방법에 대한 4가지 원칙을 제시합니다.
아직은 이론적인 부분이고 좀 더 점증될 필요가 있을 수 있다고 하면서, 소개하는 4가지 방법에 입각해서 Inception v2, v3를 만들게 됩니다.
1. Avoid representational bottlenecks
정보의 과도한 소실을 방지하기위해서 입력에서 출력으로 천천히 압축해야 합니다.feature map의 크기는 갑작스러운 축소를 방지하고 성급하게 축소되지 않도록 점진적으로 천천히 줄여야 합니다.
2. Higher dimensional representations are easier to process locally within a network.모델이 출력 쪽에 가까워질수록 더 고차원적으로 표현된 정보의 경우 Conv block을 잘게 분해할 경우 정보 표현을 향상하고, 결과적으로 네트워크를 더 빨리 학습시킬 수 있습니다.
3. Spatial aggregation can be done over lower dimensional embeddings without much or any loss in representational power.
저차원 임베딩에서는 Spatial aggregation을 수행해도 표현력의 손실 없이(혹은 거의 없이) 유지할 수 있습니다.Spatial aggregation -> 1x1 Conv를 이용한다는 부분을 보아 이미지 축소를 의미한다고 이해했다.
저차원 임베딩에서 주변 인접한 유닛들이 가진 정보가 유사한 정보를 가지고 있다고 믿고 있으며, 이 때문에 이미지 축소에 의한 정보 손실이 적다고 생각한 것 같다.
4. Balance the width and depth of the network.
모델의 너비(width)와 깊이(depth)는 무조건 크다고 좋은 것이 아니라 밸런스를 잘 맞춰서 함께 최적화가 되어야 계산량이 적절히 잘 분배가 되어서, 좋은 성능을 낼 수 있기 때문에 제한된 컴퓨팅 리소스로 더 나은 성능을 내려면 네트워크의 너비와 깊이를 균형 맞추어야 합니다.3.1. Factorization into smaller convolutions
5x5 -> 3x3 + 3x3
VGG에서 차용한 내용이라는 생각을 한다.
5x5 필터를 사용하는 것과 3x3 + 3x3 필터를 사용하는 것은 같은 효과를 내지만 5x5 필터의 계산량이 후자에 비해서 30%가량 높다고 한다.

3.2. Spatial Factorization into Asymmetric Convolutions
3x3 -> 1x3 + 3x1
추가적으로 3x3 Conv를 2x2 + 2x2로 분해할 경우 계산량에서 11%의 이득을 볼 수 있지만,
1x3 + 3x1로 분해할 경우 계산량에서 33%의 이득을 볼 수 있습니다.

하지만 실험 결과 이 방법은 네트워크의 앞부분에서는 성능이 떨어지는 것처럼 보이지만 중간 크기의 feature map이 있는 레이어에서는 잘 작동할 수 있습니다.

그렇기 때문에 중간 크기의 feature map이 있는 레이어에서는 상단과 같은 구조를 사용합니다.
4. Utility of Auxiliary Classifiers
Inception v1에서는 두 개의 Auxiliary Classifiers가 각각 다른 stage에 사용되었지만, 하위 stage의 Auxiliary Classifiers 하나를 제거하더라도 최종 성능에 악영향을 미치지 않았다고 해서 Inception v2에서부터는 2개 중에 모델 초반부인 아래에 있는 Auxiliary Classifiers는 없애버렸습니다.

5. Efficient Grid Size Reduction
feature map의 크기를 줄이기 위한 방법으로 풀링과 1x1 Conv가 있습니다.
1x1 Conv -> 풀링을 사용할 경우 계산량이 매우 커집니다.
풀링 -> 1x1 Conv를 사용할 경우 병목현상이 발생합니다.

결론적으로 두 가지 케이스 모두 사용할 수 없기에 새로운 케이스를 제안합니다.
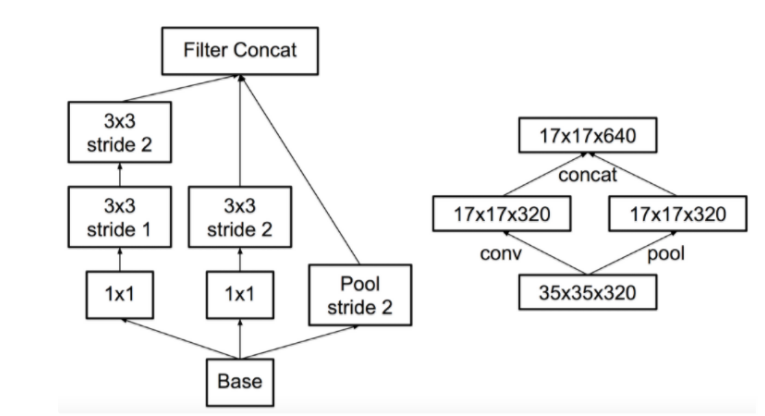
위와 같이 Conv와 pooling을 병렬로 수행하여 concat 하는 구조인데, 이의 장점으로 연산량이 낮아지며, 병목현상이 사라져 두가지 케이스의 단점을 모두 커버할 수 있게 됩니다.
6. Inception-v2
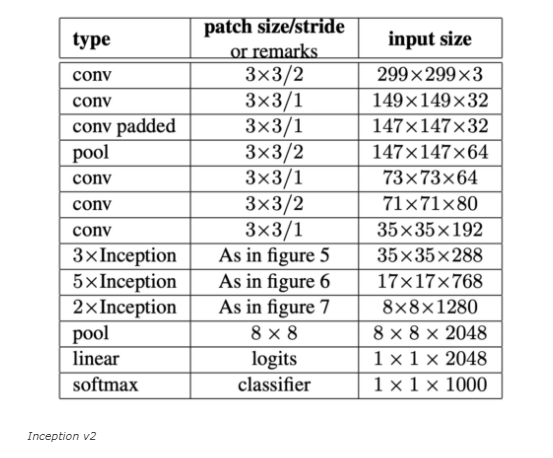
Inception-v2는 레이어 앞단은 기존의 Conv layer들과 다른 부분이 없습니다.
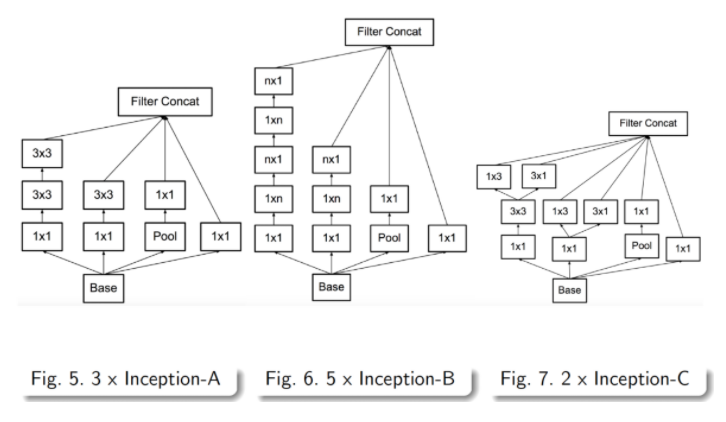
중간부터 앞에서 서술한 기본 Inception layer들이 등장하는데, figure 5, 6, 7로 표기되어 있으며,
이는 앞에서 설명한 여러 기법들이 차례차례 적용된 것입니다.
7. Model Regularization via Label Smoothing
Class가 4개라고 했을 때, 정답이 [1, 0, 0, 0]의 점수로 되어 있다면, 좀 더 Smooth 하게 [0.75, 0.25, 0.25, 0.25] 정도 점수로 해줘서 너무 강하게 확신하지 않게 해주는 것입니다.
8. Training Methodology
NVidia Kepler GPU 50개를 사용한, 학습 세부 내용은 아래와 같습니다.
Batch size: 32
Epochs: 100
Optimizer: RMSProp with decay of 0.9, and
LSR: epsilon = 1.0
Learning rate:9. Performance on Lower Resolution Input

- 그 결과, 적절하게 모델 구조를 이미지 사이즈에 맞게 잘 조절하면, 이미지가 작을수록 학습 시간이 좀 더 오래 걸려서 그렇지, 결국에는 큰 정확도의 손실 없이 모두 잘 수렴을 했다는 것을 말해주고 있습니다.
10. Experimental Results and Comparisons – Inception v3

왼쪽의 표에서 inception v2 기본 버전이 top-1 error 값이 23.4% 임을 확인 가능합니다.
여기서 각종 기능을 붙여 봅니다.
- RMSProp : Relu -> RMSProp로 optimizer를 바꿉니다.
- Label Smoothing : 위에서 설명했던 정답 라벨의 확신 정도를 줄여주는 것입니다.
- Factorized 7x7 : 위에서 설명했던 7x7 layers -> 3x3 + 3x3로 factorization 하는 것입니다.
- BN-auxiliary : 마지막 fully connected 레이어에 Batch Normalization(BN)을 적용
위의 모든 것들을 적용한 게 Inception v3입니다.
최종적인 결과는 아래의 표와 같습니다.

Inception v2와 v3를 비교했을 때 Top-1 error의 경우 23.4% -> 17.2% 로 성능이 많이 개선되었습니다.
'논문 공부' 카테고리의 다른 글